

PostgreSQL is monotlithic. It runs on a single computer, using the computer’s CPU to process queries and the computer’s block storage to store the data. That means that scaling PostgreSQL requires scaling the entire computer (both computer and storage), and that means that you’ll end up over provisioned on one or the other. Scaling is non-trivial.
Neon makes Postgres serverless. It achieves this by detaching the compute from the storage. That means that they can scale compute and storage independently, adding more compute or storage on the fly (and scale to zero!)
How is this done?
Quick recap on how relational database management systems handle data
Like most relational database management systems (RDBMS), Postgres stores its data on disk in what’s called block storage. Block storage consists of fixed sized blocks on disk (in Postgres, those are 8KB by default), and each chunk of the data that fits into a block is referred to as a page.
Before reaching this persistent storage layer, data goes from in-memory, where data processing, queries and updates happen, to the buffer pool, where pages of data are cached in memory to reduce disk I/O, to the write-ahead log (WAL) where all updates to the data in block storage are kept in a log to ensure durability, and finally to the block storage.
How Neon’s custom storage system works
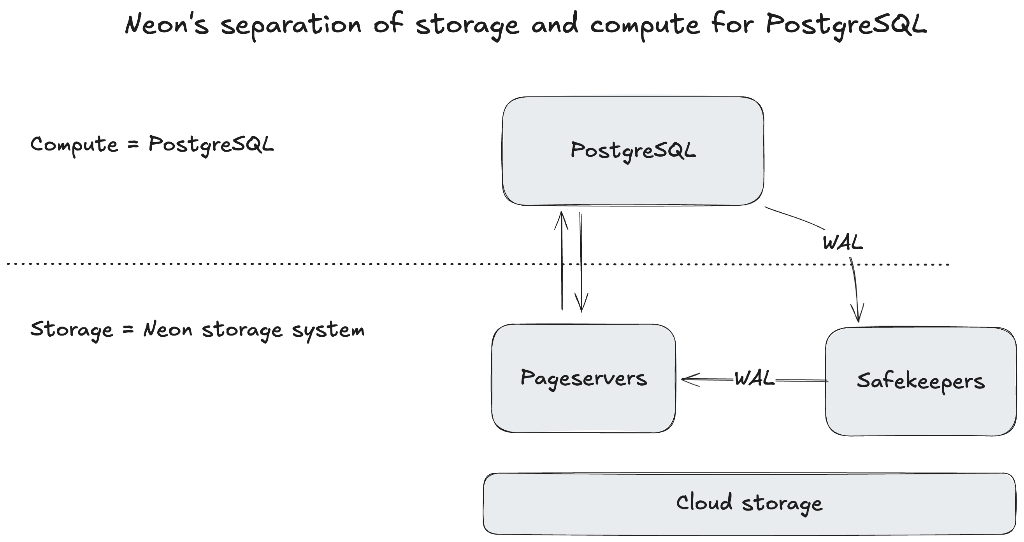
What does Neon do differently? Neon implemented a custom storage system (written in Rust) that intercepts calls to update pages in the block storage and stores these updated pages on a cloud object store instead of the computer’s disk. This decoupling enables independent scaling of compute and storage.
On the write side, it intercepts the write-ahead-log (WAL) which contains all the modifications to the Postgres’ block storage. Safekeepers ensure the WAL is persisted (with a minimum of 3 safe keepers agreeing on a persisted WAL). Then, they forward the WAL stream to the Pageservers. The Pageservers are the ones who act as the adapter between Postgres and the external cloud object store, in this “write” scenario, saving the WAL to the object store.
On the read side, the storage system intercepts reads from disk from PostgreSQL and translates these into network calls to the Pageservers. The Pageservers then construct the page that is requested by the PostgreSQL process using the WAL.
To make Neon serverless, the Neon team runs PostgreSQL on virtual machines on Kubernetes, scaling up based on CPU, local disk and memory. The data is stored on cloud storage such as Amazon S3, which effectively provides infinite scale. In other words, Neon provides vertical scaling for compute and horizontal scaling for data.
This separation of compute and storage is what enables PostgreSQL to be serverless and with automatic scale. But having access to all WAL logs makes it possible to build unique developer experiences.
A key feature of the Neon DX is data branching. Data branching allows various environments to have a “branch” of the data instantly available, instead of going through the lengthy process to spin up separate databases for each environment. That means that both the data and the schema can be changed on a branch (other databases such as Planetscale only offer schema branching).
What is the difference between Neon and Planetscale?
This question was asked in a CMU database systems lecture where Neon was a guest speaker.
Planetscale is based on Vitess which is MySQL-compatible, developed at YouTube. Planetscale does horizontal scaling across shards, with distribution of requests happening before hitting the MySQL shards. With Neon, the scaling happens after PostgreSQL when it writes to the file system.
Neon has a single writer node, so it can scale writes vertically with added CPU, RAM and storage, but reads are scaled horizontally with read replicas.
One could look at Planetscale/Vitess as MySQL for very large enterprises that need very high write throughput (YouTube-scale) vs Neon that is serverless and efficient for small-decently large applications. Built on the fact that Planetscale has horizontal scaling for write and reads, but Neon has only vertical scaling for write, horizontal for reads.
What is the difference between Neon and Aurora
Neon is Postgres-specific, which enables it to benefit from Postgres’ extensive and open ecosystem. Amazon Aurora is the main other option for a database with split compute and storage to allow for scaling, though it doesn’t exactly scale to 0. Neon is also open source, whereas Aurora is not.
References: https://www.youtube.com/watch?v=dSxV5Sob5V8&list=PLSE8ODhjZXjYDBpQnSymaectKjxCy6BYq&index=4, https://neon.tech/blog/hello-world, https://news.ycombinator.com/item?id=31536827