

You’ve probably used MCP servers without even knowing it—whether it’s the filesystem, Git, or Puppeteer tools in your favorite AI agent. It’s sort of magical; it just works. You can easily build your own MCP server for your tools or make your agent an MCP client by using the Anthropic’s MCP SDK. But have you ever wanted to take a peek under the SDK to understand how it works at the protocol level?
Recap on what MCP is and why it matters
Model Context Protocol (MCP) is the open standard proposed by Anthropic to make it easier for AI applications to interact with external tools. You’ve heard the USB-C analogy before; let’s focus on why it’s so important.
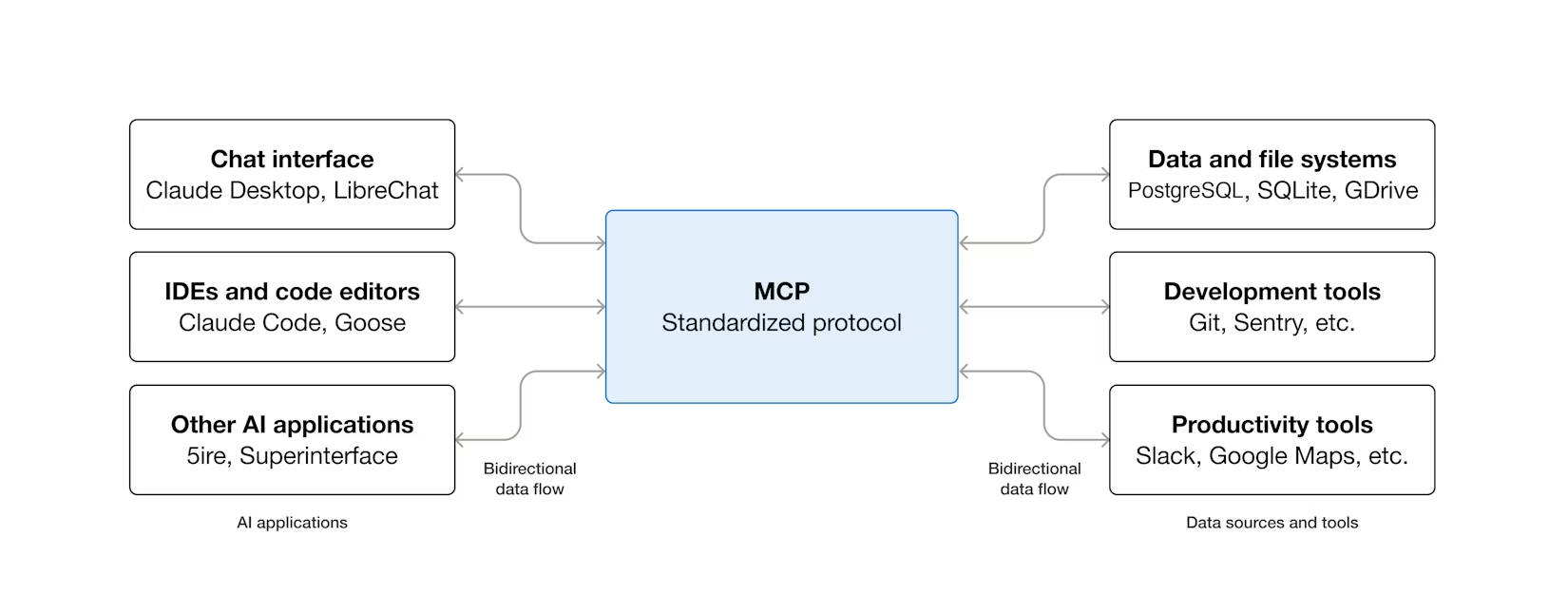
When building agents, you want to connect your LLMs to tools to perform actions—traditionally done via function calling, where a function’s signature is passed as context to the LLM so it can decide to execute the function. But what if you aren’t the one building the agent? What if you want your tool to be accessible to any agents like Claude Desktop?
That’s what MCP solves. By implementing the MCP protocol, your tool becomes accessible to any MCP-compatible client without requiring the client to know anything about your specific tool.
It’s an open plugin system, but open to all tools and agents speaking MCP.
Learning how MCP works by looking at logs
When trying to understand how MCP works, you can read the MCP documentation. But I find that the best way to understand how things work is to look at what’s under the hood of the SDKs and abstractions.
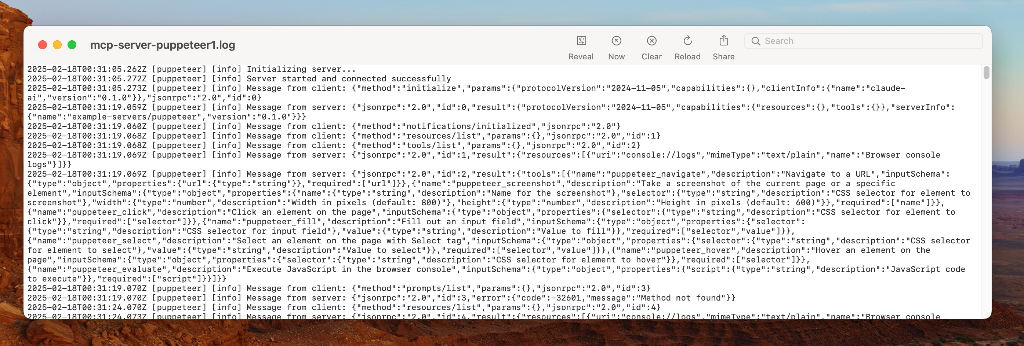
At its core, MCP is surprisingly simple—it’s built on JSON-RPC 2.0, a lightweight remote procedure call protocol using plain JSON messages. You can read all of the messages between an MCP server and client just by looking at logs. MCP messages are the same when the client and server are running locally (e.g. Claude Desktop connecting to a local MCP server over stdio) or remotely over HTTP(S).
Let’s take a look at what messages are sent between an MCP client (an LLM agent) and server upon startup for a random weather MCP server I built.
POST /mcp HTTP/1.1
Host: mcp-server.example.com
Content-Type: application/json
{
"method": "initialize",
"params": {
"protocolVersion": "2025-11-25",
"capabilities": {
"roots": {}
},
"clientInfo": {
"name": "claude-code",
"version": "2.0.76"
}
},
"jsonrpc": "2.0",
"id": 0
}This is the startup flow for an MCP client connecting to an MCP server (ie. this is what Claude Code does when it starts up with an MCP server configured). It shows three key interactions:
-
method: initialize: The first message that a client needs to send to a server to connect, establishing the protocol version and client capabilities.
-
method: notifications/initialized: The confirmation message from the server that the client is properly connected.
-
method: tools/list: The message that the client sends to learn about the tools that the MCP server provides. This is how the client discovers what capabilities are available.
Check out the logs. By the end of this startup flow, the agent (MCP client) knows that it can use the get-weather-forecast and get-weather-alerts tools provided by the server, along with what parameters are required to call it. This information is added to the prompt to allow the LLM to decide when to call these tools based on the subsequent user input.
These 3 methods, initialize, notifications/initialized, and tools/list, are 3 of the standard MCP messages that every MCP client/server interaction will understand. The entire list is available in the schema documentation.
Example: Calling a tool
Once the client has discovered the tools, it can call them using the tools/call method. Here is an example of a agent deciding to call the get-weather-forecast tool to respond to the user’s message.
Let’s pause for a minute to look at how these messages actually work. Look at the fields of MCP request messages:
- method is a standard field that indicates exactly what action the MCP client wants to perform (like
tools/listortools/call). - params is a separate section that contains the specific arguments for that method, such as the name of the tool being called and the input parameters generated by the LLM (according to the tool’s schema from the
tools/listresponse). - id is used to correlate requests with responses.
And when looking at the response, we can see:
- result contains the output of the tool call, such as the weather forecast data in this case.
- id matches the request’s id to link the response back to the original call.
This tool interaction shows the core of what MCP is for: allowing an LLM to interact with the external world. The client (e.g. Claude) decides to use a tool, generates the necessary parameters, and sends a tools/call request. The server executes the tool and returns the result, which is used by the agent to respond to the user.
Convenience with Prompts
MCP supports a handful of other useful, though less popular features. Let’s focus on prompts next, since you’ll likely come across them in a few MCP servers.
Prompts are pre-defined templates, written by the developers of the MCP server you’re using, who likely know how to prompt their MCP server more effectively and efficiently than you.
Unlike tools (which the LLM picks), prompts are user-driven: the user selects a prompt depending on what they want to achieve. For example, in GitHub Copilot, you can trigger a prompt using a command like /mcp_github-mcp_AssignCodingAgent along with the parameters required for the prompt, in this case repository:thomasgauvin/testing-email-service.
When this prompt is called, the GitHub MCP server returns a conversation template that guides the LLM on how to handle GitHub issues. You can see the full prompt text in the response log above.
Note that the Model Context Protocol supports many other interesting features, such as Resources, and Sampling, but these features are less prevalent (the most popular MCP servers contain only tools) so I won’t cover them here.
You can see the Model Context Protocol in action for yourself by looking at MCP server logs locally with Claude, or by using the MCP Inspector to manually trigger and debug an MCP server. In fact, I highly encourage that you try to do this with some of the MCP servers listed in the MCP repository of servers.
But I wanted to go a step further and have an easier way to visualize MCP messages in real-time without having to dig through logs. So I built MCP Interceptor.
Enter MCP Interceptor - a remote MCP proxy
MCP Interceptor is a simple web tool that acts as a proxy to a remote MCP server (that uses the Streamable HTTP Transport). You provide the URL of the MCP server you want to use and MCP Interceptor gives your a proxy URL that will log all MCP messages in real-time as they are sent between the client and server.
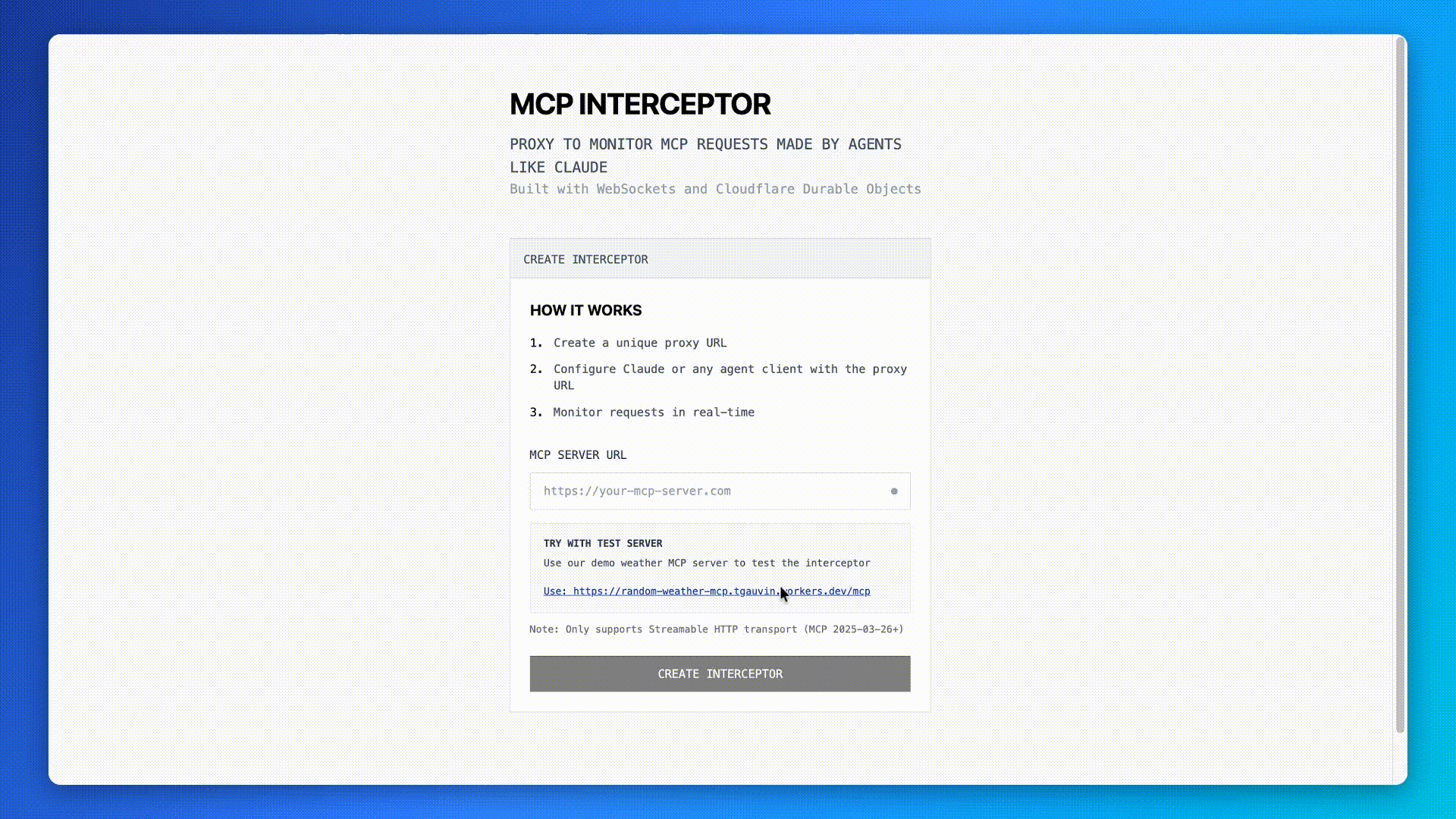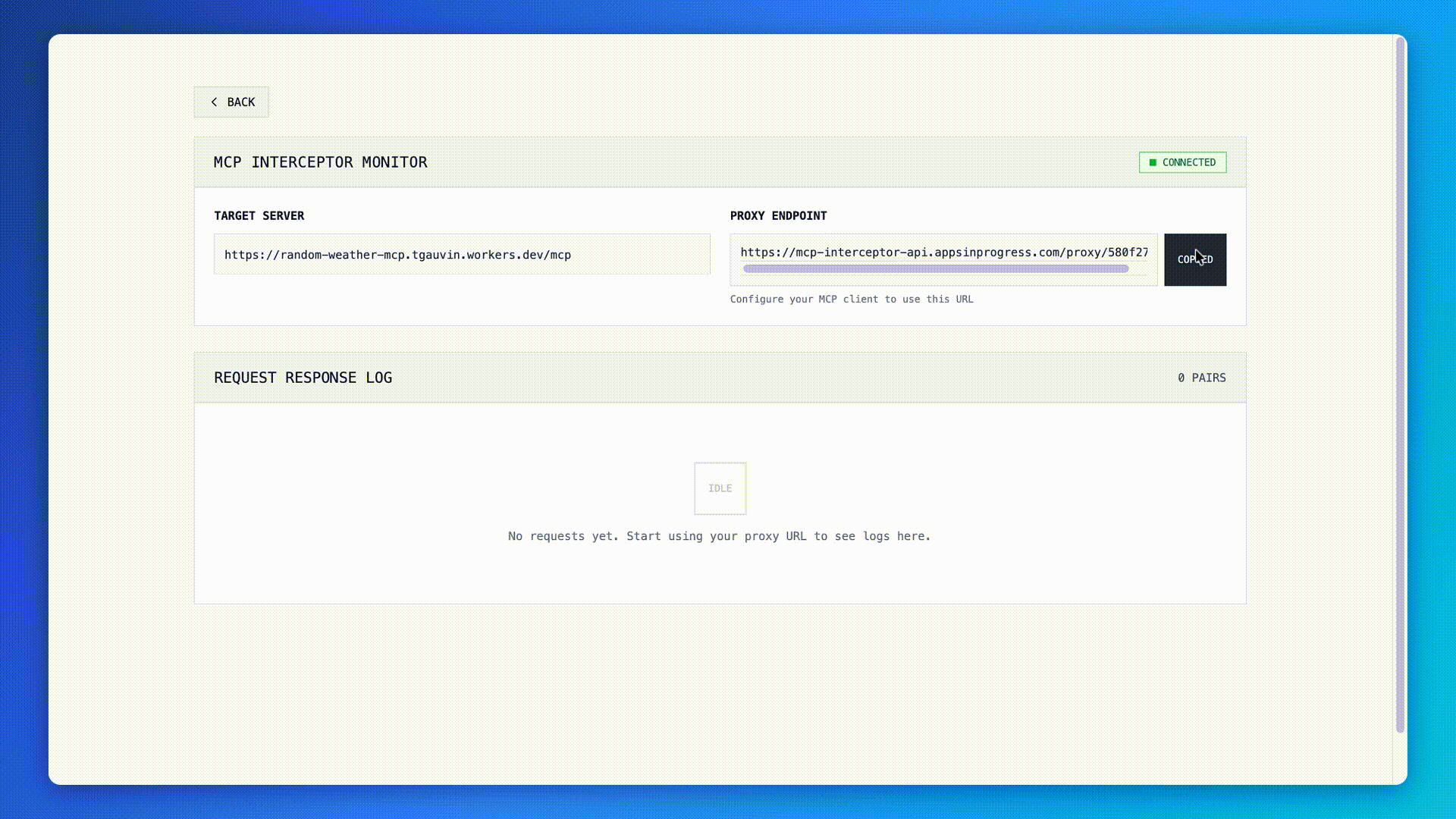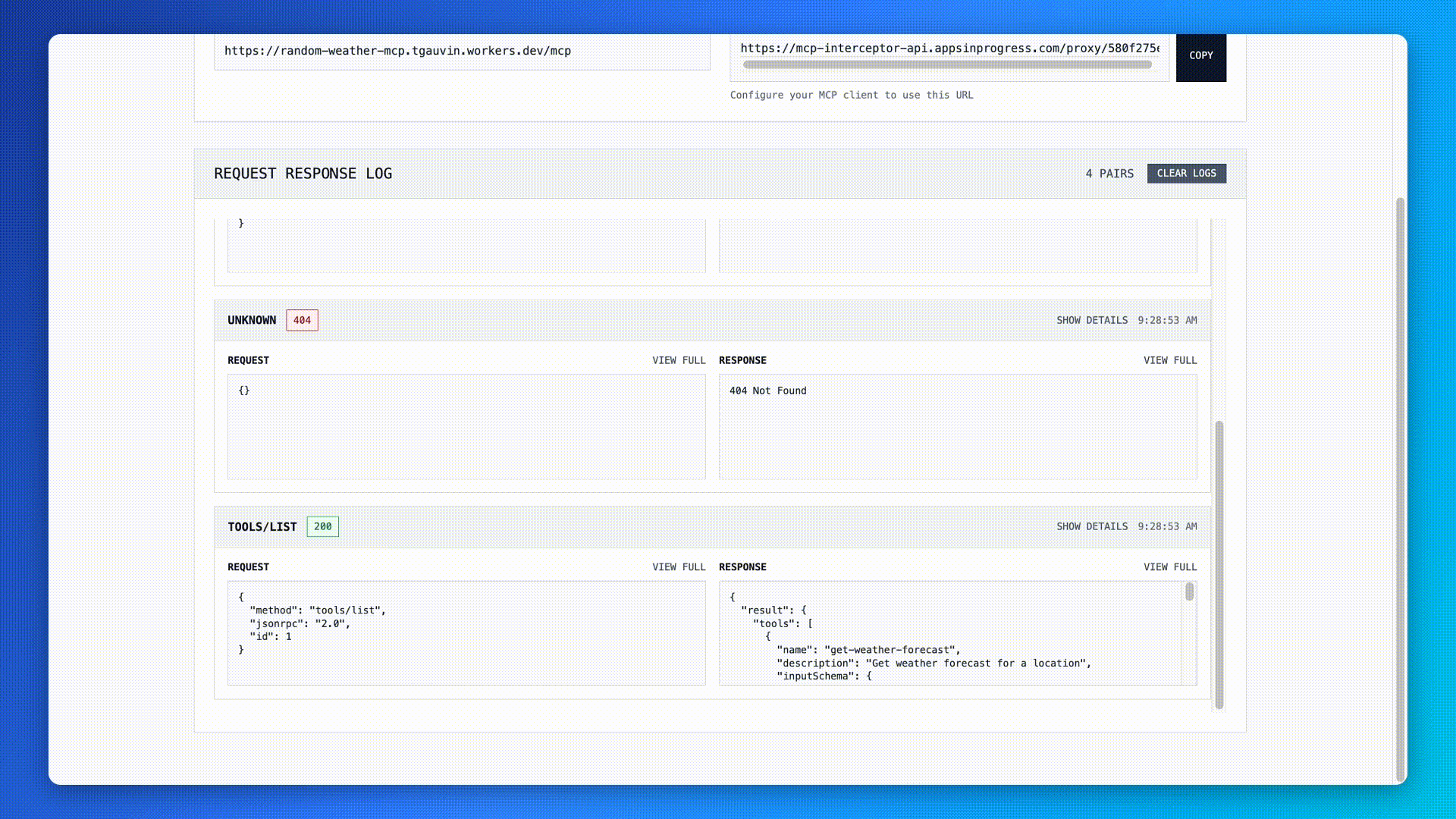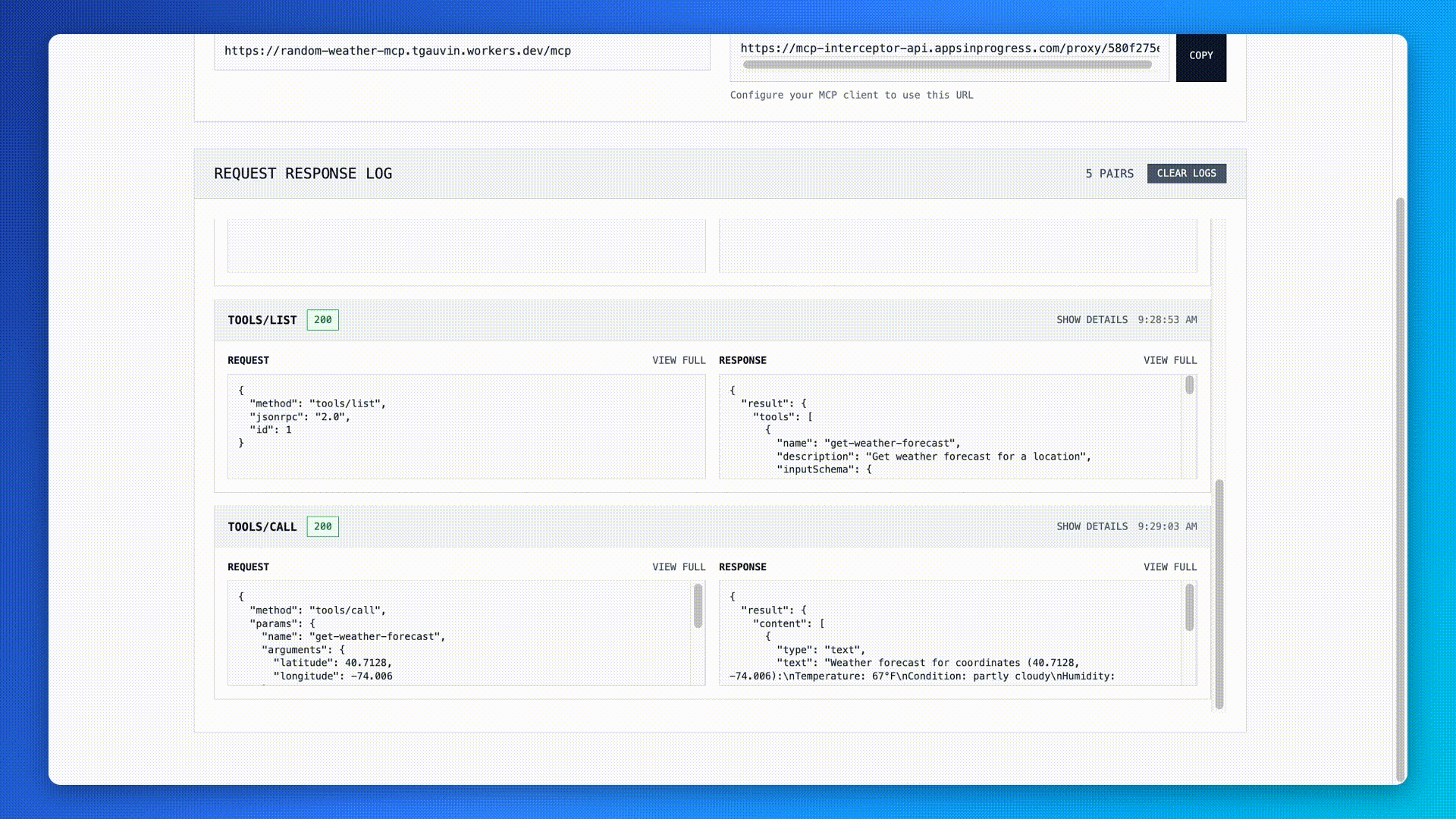
For instance, When you get your proxy URL, you can configure your MCP client of choice, (in this case Claude Code) to use MCP Interceptor. With Claude Code, run the following command claude mcp add --transport http demo-weather <MCP-Interceptor-Proxy-Endpoint-Here> . Then, when you load up Claude Code, you’ll observe that it will immediately connect to the MCP server and run the tools/list command to learn what tools the MCP server provides.
Try it out yourself! https://mcp-interceptor.appsinprogress.com/ You can even test it with the sample random weather MCP server I built as part of this process.
What started out as an attempt to peek behind the curtain of the MCP SDKs ended up turning into a cool little side project that uses Cloudflare Durable Objects and Workers under the hood to simplify visualizing MCP logs in real-time (the code is available here).
In the end, with MCP, there is no magic: it’s LLMs generating the parameters to call functions, with MCP acting as the standard protocol that makes it easy for new tools to be added to clients on the fly.
Note: This post was originally published in August 2025. It has been updated in January 2026 to include content edits and request visualizations.